Performance testing is often a major bottleneck in the productization of software. Performance tests are normally ran late in the development lifecycle, require a lot of manual intervention and regressions are detected often after a long bake time.
Shifting from versioned products to continual delivered services changes the risk profile of performance regressions and requires a paradigm shift for managing performance testing.
Problem Statement
How can performance engineering teams enable Eng / QE / SRE to integrate Performance Testing into their workflows, to reduce the risk that performance regressions propagate through to product releases and production services?
Typical Product Workflow
A typical "boxed product"[1] productization workflow can be represented by;

The key issues that this type of workflow has;
There is a break in continuity between
tag buildandreleasestages of the CI Build pipelineDevelopment, build and performance testing are performed by different teams, each passing async messages between teams
The feedback loop to developers is manual and slow
There is a lot of manual analysis performed, often with ad-hoc data capture and reporting
The above scenario generally develops due to a number of factors;
Dedicated performance environments are costly and difficult to setup and manage
Performance Analysis (including system performance monitoring and analysis) is generally a specialized role, concentrated in small teams
The time required to manage reliable/accurate benchmarks is often a time sink
Whats the problem?

The further into the development cycle performance testing occurs, the more costly it is to fix performance bugs.[2]
Over the years, methodologies have developed to allow functional tests to be performed earlier in the development lifecycle, reducing the time between functional regressions being introduced and discovered.
This has the benefits of;
Push earlier into development cycle
Discover quality issues more quickly
Reduce cost to fix
Reduce test & deploy cycles
Functional issues are typically easier to fix than Performance issues because they involve specific, reproducible errors in the software’s behavior; therefore, performance testing should be "Shifted-Left" in the same way that functional testing has been
What does it mean to Shift left?
In the traditional Waterfall model for software development, shift left means pushing tests earlier into the development cycle;

In the Agile world
For continually delivered services, "shifting left" incudes an additional dimension;

Not only do we want to include performance tests earlier in the dev/release cycle, we also want to ensure that the full suite of performance tests (or any proxy performance tests) captures performance regressions before multiple release cycles have occurred.
Risks in the managed service world
Managed services changes the risk associated with a software product;
Multiple, Rapid dev cycles; the time period between development and release is greatly reduced
Probability of releasing a product with a performance regression increased
Performance Regressions will effect all customers, immediately
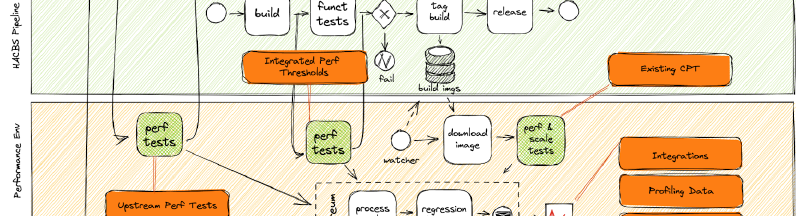
Performance Shift-Left Workflow
In order to manage the changed risk profile of managed services compared to boxed products, an new methodology is required;

In a "Shifted-left" model;
Code Repository Bots allow performance engineers to initiate Upstream Performance Tests against open Pull Requests, returning comparative performance data to workflow that the engineer uses in the day-to-day job.
Integrated Performance Threshold tests provide automated gating of acceptable levels of performance
Continual Performance Testing allows for analyzing trends over time, scaling, soak and chaos type testing, asynchronously from the CI/CD build pipeline
Automated Regression Detection provides automated tooling for detecting catastrophic performance regression related to a single commit, or creeps in performance degradation over time
Continual analysis is performed by experienced engineers, but the process does not require manual intervention with each release.
Engineers are free to focus on implementing features and not worry about performance regressions. When regressions are detected, the information they need to identify the root cause is readily available, in a suitable format.
Code Repository Bots
Code Repository Bots initiate performance tests against PR’s. Their purpose is to allow engineers to make a decision on whether to merge a PR or not. The results need to be actionable by engineers. Profiling data should also be provide to allow engineers to understand what their changes are doing
Receive report & analysis of impact of changes to key performance metrics
Allow automated capture of profiling data of system under load, allowing engineers to see what their changes are doing under realistic scenarios
Triggered from CI/CD pipeline
Automatic / Manual
Performance Results reported in PR
Actionable data for engineers (results/profiles added the PR’s to keep all information co-located for each PR)
Integrated Performance Thresholds
The aim of Integrated Performance Tests is to determine whether a release meets acceptable levels of performance with respect to customer expectations, not to capture changes over time. The results need to be automatically calculated and should provide a boolean Pass/Fail result.
Pass/Fail criteria - the same as functional tests, the performance should be either be acceptable, or not-acceptable
Fully automated - not manual intervention / analysis
Focused on user experience
Threshold based?
Integrated with QE tools
Portable Tests
Limits Thresholds defined by CPT
Continual Performance Testing
The aim of Continual Performance Testing is to perform larger scale performance workloads, that can take time to perform.
These tests can include;
Large scale end-to-end testing
Soak tests
Chaos Testing
Trend analysis
Scale testing
Automated tuning of environment
Detailed profiling and analysis work
Automatic Change Detection
Automated tools that allow detection of changes in key performance metrics over time. Tools such as Horreum[3] can be configured to monitor key performance metrics for particular products and cen be integrated into existing workflows and tools to raise alerts/block build pipelines when a significant change is detected.
The key to incorporating automated tools into the CI/CD pipeline is for the ability for the tools to integrated seamlessly into existing CI/CD pipelines and provide accurate, actionable events.
Continual Profiling & Monitoring
Not all performance issues will be caught during the development lifecycle. It is crucial that production systems are capturing sufficient performance related data that allows performance issues to be identified in production. The data needs to be of sufficient resolution to be able to perform a root case analysis during a post mortem, or provide information to be able to test for the performance issue in the CI/CD pipeline.
Integration with Analytical Tools
In order to understand the performance characteristic of a service running in production, all of the performance metrics captured at different stages of testing (dev, CI/CD, production) need to be accessible for a performance engineer to analyse.
This requires the performance metrics to be collocated, and available for analysis by tools, e.g. statistical analysis tools.
Further Tooling to assist Product Teams
Other tools that can help product teams with performance related issues are;
Performance Bisect: perform an automated bisect on source repository, running performance test(s) each time to automatically identify the code merge that introduced the performance regression
Automated profiling analysis: AI/ML models to automatically spot performance issues in profiling data
Proxy Metrics: System metrics captured during functional testing that will provide an indication that a performance/scale issue will manifest at runtime
Automatic tuning of service configuration: Using Hyper-Parameter Optimization[4] to automatically tune configuration space of a service to optimize the performance for a given target environment/workload